Yuchen Fan 范雨晨

Ph.D. Candidate
Department of Electrical and Computer Engineering
University of Illinois at Urbana-Champaign
Email: yuchenf4 [at] illinois [dot] edu
Bio
I am currently a fifth-year Ph.D. student advised by Prof. Zhi-Pei Liang and Prof. Thomas S. Huang.
My research interests include image restoration, video understanding and segmentation, and speech.
Research Highlights
Image Restoration
Neural Sparse Representation for Image Restoration
Yuchen Fan, Jiahui Yu, Yiqun Mei, Yulun Zhang, Yun Fu, Ding Liu, Thomas S. Huang
NeurIPS 2020 [Paper] [Code]
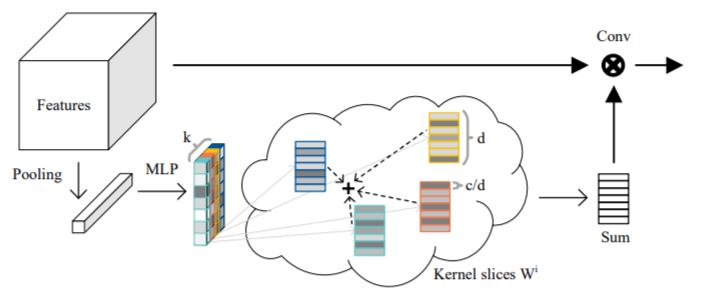 Inspired by the robustness and efficiency of sparse representation in sparse coding based image restoration models, we investigate the sparsity of neurons in deep networks. Our method structurally enforces sparsity constraints upon hidden neurons. Sparsity in neurons enables computation saving by only operating on non-zero components without hurting accuracy. Meanwhile, our method can magnify representation dimensionality and model capacity with negligible additional computation cost.
Inspired by the robustness and efficiency of sparse representation in sparse coding based image restoration models, we investigate the sparsity of neurons in deep networks. Our method structurally enforces sparsity constraints upon hidden neurons. Sparsity in neurons enables computation saving by only operating on non-zero components without hurting accuracy. Meanwhile, our method can magnify representation dimensionality and model capacity with negligible additional computation cost.
Scale-wise Convolution for Image Restoration
Yuchen Fan, Jiahui Yu, Ding Liu, Thomas S. Huang
AAAI 2020 [Paper] [Code]
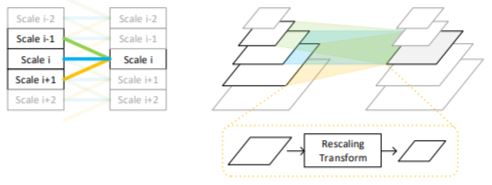 We show that properly modeling scale-invariance into neural networks can bring significant benefits to image restoration performance. Inspired from spatial-wise convolution for shift-invariance, “scale-wise convolution” is proposed to convolve across multiple scales for scale-invariance. The proposed scale-wise convolution learns to dynamically activate and aggregate features from different input scales in each residual building block, in order to exploit contextual information on multiple scales.
We show that properly modeling scale-invariance into neural networks can bring significant benefits to image restoration performance. Inspired from spatial-wise convolution for shift-invariance, “scale-wise convolution” is proposed to convolve across multiple scales for scale-invariance. The proposed scale-wise convolution learns to dynamically activate and aggregate features from different input scales in each residual building block, in order to exploit contextual information on multiple scales.
Video Segmentation
Video Instance Segmentation
Linjie Yang, Yuchen Fan, Ning Xu
ICCV 2019 [Paper] [Code] [Dataset]
 We present a new computer vision task, named video instance segmentation. The goal of this new task is simultaneous detection, segmentation and tracking of instances in videos. To facilitate research on this new task, we propose a large-scale benchmark called YouTube-VIS, which consists of 2883 high-resolution YouTube videos, a 40-category label set and 131k high-quality instance masks. In addition, we propose a novel algorithm called MaskTrack R-CNN for this task. Our new method introduces a new tracking branch to Mask R-CNN to jointly perform the detection, segmentation and tracking tasks simultaneously.
We present a new computer vision task, named video instance segmentation. The goal of this new task is simultaneous detection, segmentation and tracking of instances in videos. To facilitate research on this new task, we propose a large-scale benchmark called YouTube-VIS, which consists of 2883 high-resolution YouTube videos, a 40-category label set and 131k high-quality instance masks. In addition, we propose a novel algorithm called MaskTrack R-CNN for this task. Our new method introduces a new tracking branch to Mask R-CNN to jointly perform the detection, segmentation and tracking tasks simultaneously.
YouTube-VOS: Sequence-to-Sequence Video Object Segmentation
Ning Xu, Linjie Yang, Yuchen Fan, Jianchao Yang, Dingcheng Yue, Yuchen Liang, Brian Price, Scott Cohen, Thomas S. Huang
ECCV 2018 [Paper] [Dataset]
 Learning long-term spatial-temporal features are critical for many video analysis tasks. End-to-end sequential learning to explore spatial-temporal features for video segmentation is largely limited by the scale of available video segmentation datasets. To solve this problem, we build a new large-scale video object segmentation dataset called YouTube Video Object Segmentation dataset (YouTube-VOS). Our dataset contains 3,252 YouTube video clips and 78 categories including common objects and human activities.
Learning long-term spatial-temporal features are critical for many video analysis tasks. End-to-end sequential learning to explore spatial-temporal features for video segmentation is largely limited by the scale of available video segmentation datasets. To solve this problem, we build a new large-scale video object segmentation dataset called YouTube Video Object Segmentation dataset (YouTube-VOS). Our dataset contains 3,252 YouTube video clips and 78 categories including common objects and human activities.
Speech Synthesis
Multi-speaker modeling and speaker adaptation for DNN-based TTS synthesis
Yuchen Fan, Yao Qian, Frank K. Soong, Lei He
ICASSP 2015 [Paper]
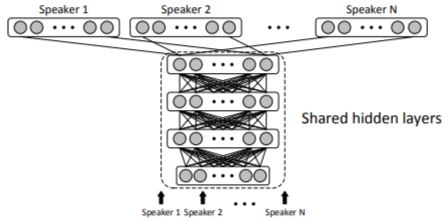 The DNN-based TTS synthesis can not take advantage of huge amount of training data from multiple speakers. We propose an approach to model multiple speakers TTS with a general DNN, where the same hidden layers are shared among different speakers while the output layers are composed of speaker-dependent nodes explaining the target of each speaker. We further transfer the hidden layers for a new speaker with limited training data and the resultant synthesized speech of the new speaker can also achieve a good quality in term of naturalness and speaker similarity.
The DNN-based TTS synthesis can not take advantage of huge amount of training data from multiple speakers. We propose an approach to model multiple speakers TTS with a general DNN, where the same hidden layers are shared among different speakers while the output layers are composed of speaker-dependent nodes explaining the target of each speaker. We further transfer the hidden layers for a new speaker with limited training data and the resultant synthesized speech of the new speaker can also achieve a good quality in term of naturalness and speaker similarity.
TTS synthesis with bidirectional LSTM based recurrent neural networks
Yuchen Fan, Yao Qian, Feng-Long Xie, Frank K. Soong
INTERSPEECH 2014 [Paper]
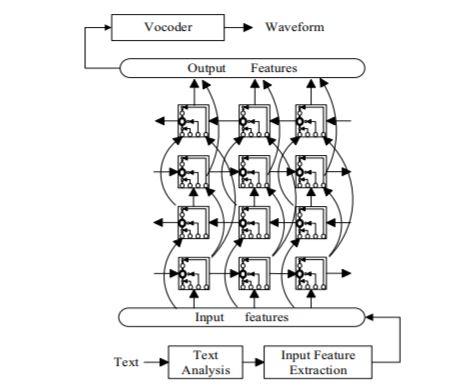 Long time span contextual effect in a speech utterance is still not easy to accommodate, due to the intrinsic, feed-forward nature in DNN-based modeling. In this paper, Recurrent Neural Networks (RNNs) with Bidirectional Long Short Term Memory (BLSTM) cells are adopted to capture the correlation or co-occurrence information between any two instants in a speech utterance for parametric TTS synthesis. The speech trajectory generated by the BLSTM-RNN TTS is fairly smooth and no dynamic constraints are needed.
Long time span contextual effect in a speech utterance is still not easy to accommodate, due to the intrinsic, feed-forward nature in DNN-based modeling. In this paper, Recurrent Neural Networks (RNNs) with Bidirectional Long Short Term Memory (BLSTM) cells are adopted to capture the correlation or co-occurrence information between any two instants in a speech utterance for parametric TTS synthesis. The speech trajectory generated by the BLSTM-RNN TTS is fairly smooth and no dynamic constraints are needed.
Education
 University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign
Ph.D of Electrical and Computer Engineering
2016 - Present
 Shanghai Jiao Tong University
Shanghai Jiao Tong University
Bachelor of Computer Science, ACM Honored Class, Zhiyuan College
2010 - 2014
Working Experiences
 Facebook Reality Labs
Facebook Reality Labs
Research Intern
Summer 2020
 Waymo
Waymo
Computer Vision & ML Research Intern
Summer 2019
 Google
Google
Software Engineering Intern
Summer 2018
 Jump Trading Labs
Jump Trading Labs
Student Consultant
2016 - 2018
 Microsoft Research Asia
Microsoft Research Asia
Visiting
2014 - 2016
Professional Activities
- Workshop organizer: Large-scale Video Object Segmentation Challenge
- Conference reviewer: ICLR, NeurIPS, CVPR, ICCV, ECCV, AAAI, WACV
- Journal reviewer: IEEE Transactions on Image Processing (TIP), IEEE Transactions on Multimedia
Honors and Awards
- 2020 NTIRE Video Deblurring Challenge Winner (2nd)
- 2019 NTIRE Video Restoration Challenge Winner (2nd)
- 2018 NTIRE Single Image Super-Resolution Challenge Winner (1st)
- 2017 NVIDIA AI City Challenge Winner (1st)
- ASC14 Student Cluster Competition Champion (1st)